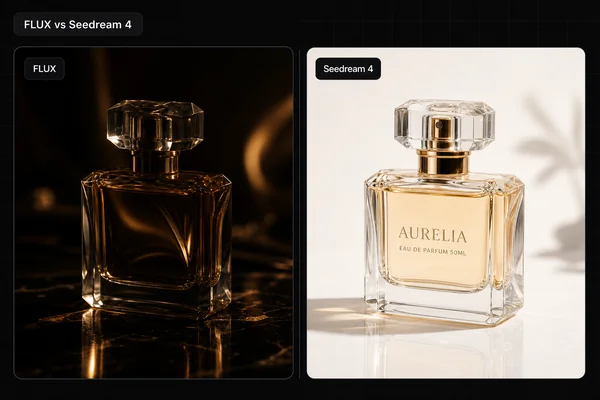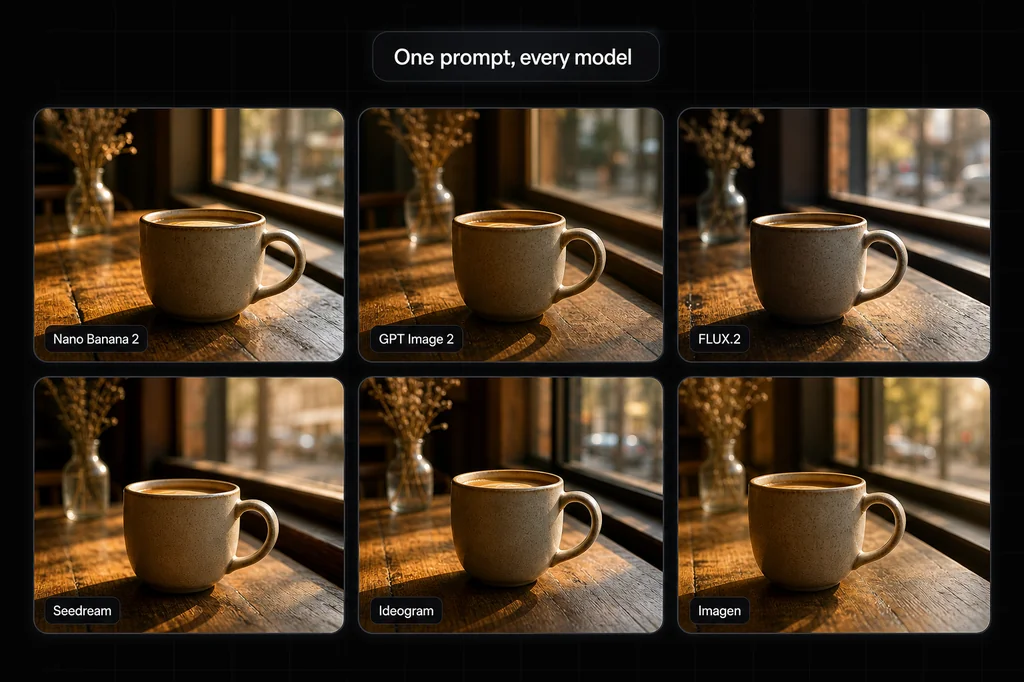
Most "prompt guide" advice is folklore copied between blogs. So I tested it. The short version: there is one framework that works across every major model, and a small set of real per-model quirks on top. Get the framework right and you are most of the way there. The quirks decide the last 10 percent.
This guide covers the underlying models, Nano Banana 2, GPT Image 2, Seedream 4.5, FLUX.2 Pro, and Ideogram V3, not the apps wrapped around them. If you want to know which model to pick for a given job, that is the product photography model roundup. This post is about how to talk to whichever one you chose.
The shared framework (works on every model)
- Write natural language, not keyword soup. Describe the scene the way you would to a person. Stacking praise tags like "4k, ultra detailed, masterpiece, award winning, 8k" does not help. In testing it added nothing and, if anything, flattened the result into something more generic.
- Lead with the subject. Put the most important thing first. Models weight the front of the prompt, so "a matte black serum bottle on marble, soft morning light" beats burying the bottle after a paragraph of mood.
- Be specific, then stop. Name the things that matter (material, lighting, mood, camera or lens for photoreal), and trust the model with the rest. Over-specifying tiny details ("size medium, three buttons") tends to confuse more than it controls.
- Phrase exclusions positively where negatives are not supported. Some models ignore negative prompts entirely (see FLUX below). Instead of "no blur," write "sharp focus." Instead of "no people," write "empty street."
- Keep it tight. One to three sentences is the sweet spot for most models; FLUX likes roughly 15 to 75 words. Longer is not better.
- Iterate by editing, not restarting. The strongest models take conversational follow-ups ("now make the label gold, keep everything else") instead of a fresh prompt each time.
Two pieces of folklore I tested and can put to rest
"Add quality tags to make it sharper." I ran the same cafe scene on Nano Banana 2 twice, once as a plain description and once with the full "4k, masterpiece, award winning, hyperrealistic, 8k" tag stack. The plain-language version came out richer and more intentional. The tag stack added no sharpness and produced a flatter, more stock-looking frame. Quality tags are noise.
"Use a negative prompt to remove things." Not on every model. I prompted FLUX.2 Pro for "a busy city street" with a negative prompt of "people, cars, vehicles." The result was full of people and cars. The CLI accepted the flag without complaint, but the model ignored it. On FLUX.2 Pro you have to describe the absence positively, because the negative does nothing.
Per-model quirks (tested)
| Model | What it rewards | Negative prompt | Text rendering | Cost / speed |
|---|---|---|---|---|
| Nano Banana 2 | Conversational prompts, 1 to 3 sentences, edits | Supported | Clean, including secondary text | Mid |
| Seedream 4.5 | Natural language, cinematic by default | Supported | Clean | Cheap, the best value |
| FLUX.2 Pro | Subject-first, 15 to 75 words, no weight syntax | Ignored, go positive | Main label good, can garble small text | Cheapest |
| Ideogram V3 | Typography-oriented prompts | Supported | Strong, but can invent a brand mark | Cheap |
| GPT Image 2 | Precise instructions, spatial and layout control | Supported | Cleanest, even tiny text | Most expensive, slowest |
A note on text, because it is the question everyone asks. I had every model render a four-word product tagline. They all got the main words right, short text is basically a solved problem now. Where they diverged was incidental text: FLUX put gibberish on a tube cap, Ideogram invented a brand name that was never in the prompt, while Nano Banana 2, Seedream 4.5, and GPT Image 2 kept the secondary text clean. So if a layout has fine print, lean toward the last three. If it is just a headline, any of them is fine.
Prompting video models
The same framework holds for video, with two additions:
- Use camera language and motion verbs. "Slow dolly in, shallow depth of field, rack focus to the rim" is followed faithfully by Veo 3.1; in testing it dollied in and pulled focus exactly as asked. Generic prompts get generic motion.
- Put spoken lines in quotes on models with native audio. Kling 2.6 Pro, Veo 3.1, and Seedance 2.0 generate sound; a quoted line is read as dialogue. Minimax Hailuo 02 and WAN 2.5 have no audio, so do not bother.
For the full image-to-video behavior breakdown, see the best AI video model for product ads roundup.
FAQ
Do quality tags like "4k, masterpiece" improve AI images? No. On modern models they add nothing and can make the output more generic. Describe the scene in plain language instead.
Why is my negative prompt being ignored? Some models, including FLUX.2 Pro, do not support negative prompts even when the tool accepts the flag. Phrase the exclusion positively ("empty street" rather than "no people").
Which model is best for text in images? For a short headline, any current model handles it. For fine print and secondary labels, GPT Image 2, Nano Banana 2, and Seedream 4.5 were the cleanest in testing; FLUX and Ideogram sometimes hallucinate incidental text.
Should prompts be long or short? Short. One to three sentences for most models, roughly 15 to 75 words for FLUX. Length does not buy quality.
The bottom line
The framework is the 90 percent: natural language, subject first, positive phrasing, kept short. The quirks are the last 10 percent, and they are worth knowing because they are where the folklore is wrong. The fastest way to internalize them is to run the same prompt across a few models and watch what changes. You can do that from one place, switching models with a flag, using the Masonry CLI.